Descriptive Analysis
Descriptive statistics are informative statistics that describe datasets. Measures of central tendency are a type of descriptive statistics. Measures of central tendency include the Mean (average), Median (middlemost data point), and Mode (most common data point) of a datset.
This example will get measures of central tendency for the respondents' ages, the 'age' variable.
To get measures of central tendency, click on 'Analyze' in the toolbar at the top of the Data Editor window. Then, click 'Descriptive Statistics' in the dropdown menu and 'Frequencies' in the side menu. (Please note: this tutorial recommends using the 'Frequencies...' function rather than the 'Descriptives...' function to get measures of central tendency because the 'Frequencies...' function offers options for more measures of central tendency than does the 'Descriptives...' function.)
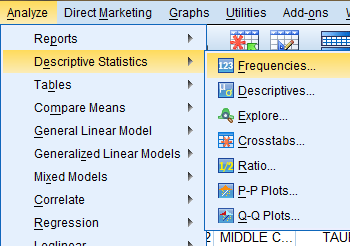
In the Frequencies dialog box that pops up, double click on the variable of interest (Age of Respondents) in the variable list to add it to the 'Variable(s):' field. If you would like your output to display frequency tables as well, select the 'Display frequency tables' box. Then, click 'Statistics...'
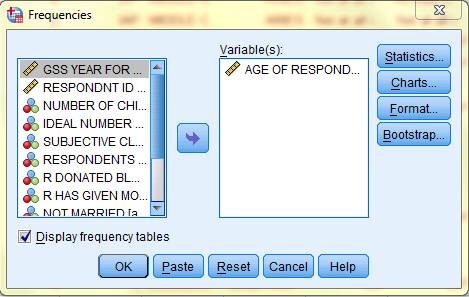
In the Frequencies: Statistics dialog box that pops up, check off mean, median, and mode, and any other desired statistics. Then, click 'Continue.' Back in the Frequencies dialog box, click OK, and the measures of central tendency will be displayed in a table in the SPSS Viewer output window.
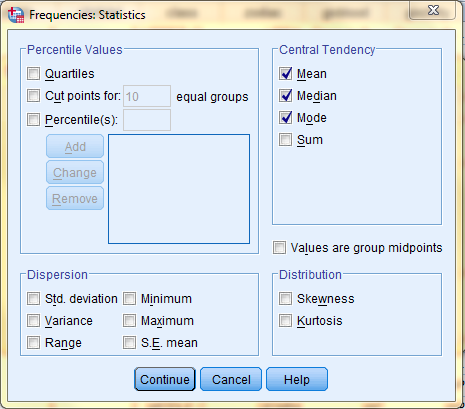
In the SPSS Viewer window, the output is displayed. The descriptive statistics, the measures of central tendency, are displayed in the Statistics table. (This output also includes a frequency table, Age of Respondent. In this table, the frequency of each age is displayed. For example, 12 respondents, .6% of all respondents, are age 18.)
Descriptive statistics are informative statistics that describe datasets. Measures of dispersion and variability are a type of descriptive statistics. Measures of dipersion and variability include the Minimum, Maximum, Range (the difference between the minimum and maximum), Variance (the average difference between each data value and the mean, squared), Standard Deviation (the square root of the variance), and Standard Error of the Mean (the standard deviation of the sample mean's estimated true population mean) of a datset. The greater the values of these statistics, the more varied and dispersed the distribution.
This example will get measures of variability for the respondents' ages, the 'age' variable.
To get measures of dispersion and variability, click on 'Analyze' in the toolbar at the top of the Data Editor window. Then, click 'Descriptive Statistics' in the dropdown menu and 'Descriptives...' in the side menu.
In the Descriptives dialog box that pops up, double click on the variable of interest (Age of Respondents) in the variable list to add it to the 'Variable(s):' field. Then, click 'Options...'
In the Descriptives: Options dialog box that pops up, check off Standard Deviation, Variance, Range, Minimum, Maximum, and Standard Error of the Mean, and any other desired statistics. Then, click 'Continue.' Back in the Descriptives dialog box, click OK, and the measures of dispersion and variability will be displayed in a table in the SPSS Viewer output window.
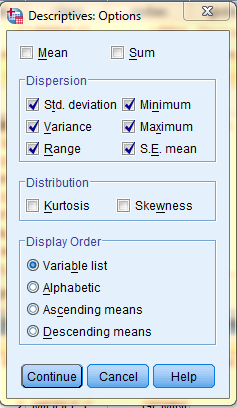
In the SPSS Viewer window, the output is displayed. The descriptive statistics, the measures of dispersion and variability, are displayed in the Descriptive Statistics table.
Descriptive statistics are informative statistics that describe datasets. Measures of distribution and normality are a type of descriptive statistics. Measures of distribution and normality include Skewness and Kurtosis.
Interpreting skewness and kurtosis:
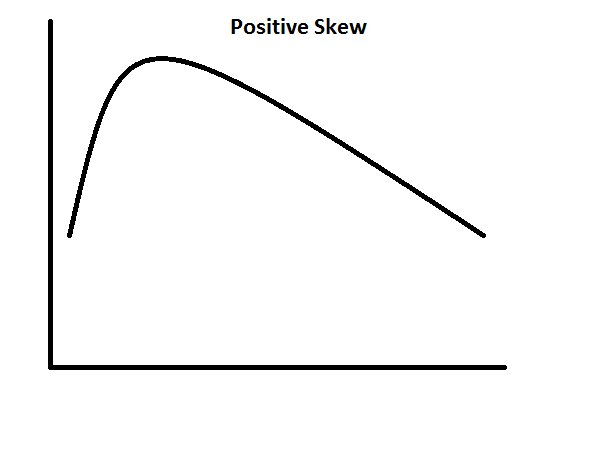
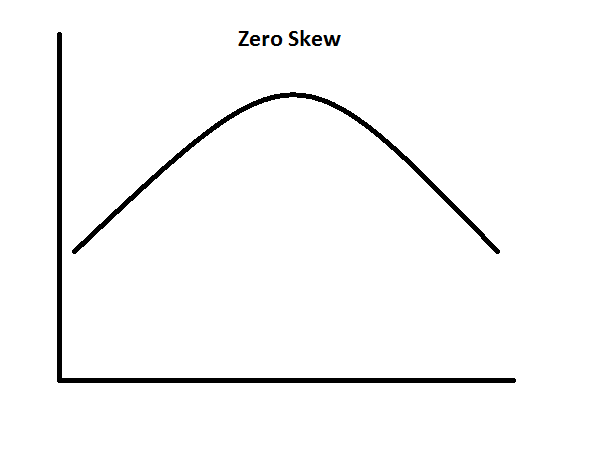
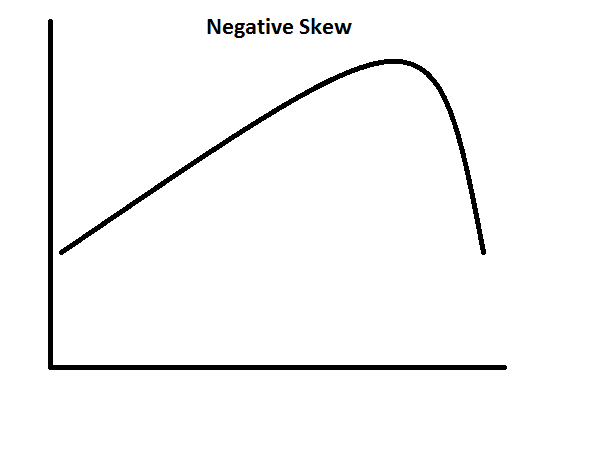
Skewness: The closer the skewness value to zero, the more symmetrical the distribution. Positive large values indicate a positively skewed distribution and negative large values indicate a negatively skewed distribution
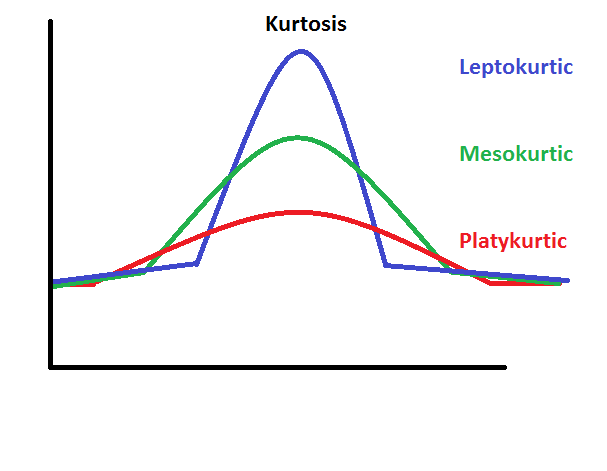
Kurtosis: The closer the kurtosis value to zero, the more normal the distribution of scores. A distribution is more leptokurtic (peaked) when the kurtosis value is a large positive value, and a distribution is more platykurtic (flat) when the kurtosis value is a large negative value.
This example will get measures of distribution and normality for the respondents' ages, the 'age' variable.
To get measures of distribution and normality, click on 'Analyze' in the toolbar at the top of the Data Editor window. Then, click 'Descriptive Statistics' in the dropdown menu and 'Descriptives...' in the side menu.
In the Descriptives dialog box that pops up, double click on the variable of interest (Age of Respondents) in the variable list to add it to the 'Variable(s):' field. Then, click 'Options...'
In the Descriptives: Options dialog box that pops up, check off Kurtosis and Skewness and any other desired statistics. Then, click 'Continue.' Back in the Descriptives dialog box, click OK, and the measures of distribution and normality will be displayed in a table in the SPSS Viewer output window.
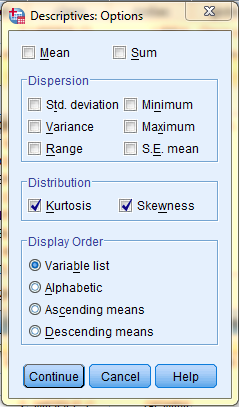
In the SPSS Viewer window, the output is displayed. The descriptive statistics, the measures of distribution and normality, are displayed in the Descriptive Statistics table.
Descriptive statistics are informative statistics that describe datasets. Z-scores are a type of descriptive statistics. Z-scores represent the number of standard deviations between each data point and the mean. A positive z-score indicates that the data point is above the mean, and a negative z-score indicates that the data point is below the mean. Z-scores are helpful in identifying outliers.
To generate z-scores, click on 'Analyze' in the toolbar at the top of the Data Editor window. Then, click 'Descriptive Statistics' in the dropdown menu and 'Descriptives...' in the side menu.
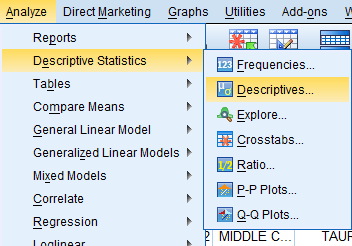
In the Descriptives dialog box that pops up, double click on the variable of interest (Age of Respondents, age) in the variable list to add it to the 'Variable(s):' field. Then, make sure the 'Save standardized values as variables' box is selected, because selecting this option instructs SPSS to create a new variable of z-scores named 'Z and the original variable’s name' (for example: Zage) in the Data Editor. While creating z-scores, SPSS can also generate a descriptives analysis in the SPSS Viewer output window. To do so, click 'Options...'
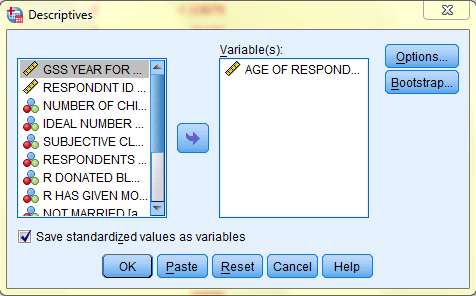
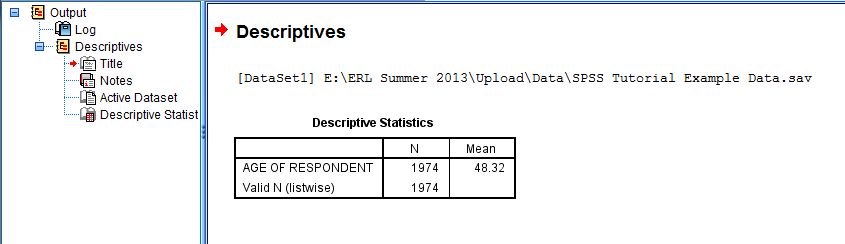
In the Descriptives: Options dialog box that pops up, check off any statistics you would like to be displayed in the SPSS Viewer output window. Here, we selected Mean because we would like the average age of the respondents to be displayed in the output (in addition to the creation of z-scores as a new variable). Then, click 'Continue.' Back in the Descriptives dialog box, click OK, and the z-scores will be added as a new variable (Zage) with each individual case having a z-score in the Data Editor. Additionally, a table with the descriptives information requested in the Options dialogue box is displayed in the SPSS Viewer output window.
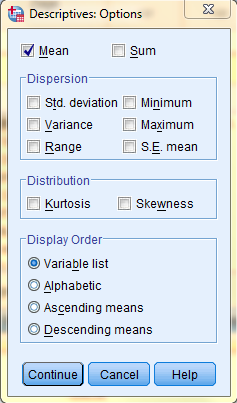
In the Data View of the Data Editor window, the z-scores have been added as a new variable (Zage) with each individual case having a z-score.
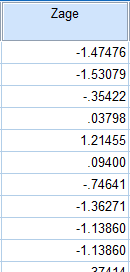
In the SPSS Viewer window, the output is displayed. The descriptive statistics (the Mean of the Age of Respondents variable) that were requested are displayed in the Descriptive Statistics table. The average age of the respondents is 48.32 years old. Please note that this descriptives table is completely independent from the z-score calculations.
Next: Frequency Analysis
Previous: SPSS Basics